|
Zu diesem Zeitpunkt sollten Sie mit CVS schon recht gut vertraut sein.
Daher werde ich an dieser Stelle mit dem Führungsstil aufhören und
einige weitere nützliche Kommandos zusammenfassend erläutern.
|
Dateien hinzuzufügen geschieht in zwei Schritten: Zuerst wird das
add-Kommando ausgeführt und anschließend das Commit. Die Datei wird
erst tatsächlich im Archiv erscheinen, wenn das Commit ausgeführt
wurde:
user@linux ~$
cvs add newfile.c
cvs add: scheduling file 'newfile.c' for addition
cvs add: use 'cvs commit' to add this file permanently
user@linux ~$
cvs ci -m "added newfile.c" newfile.c
RCS file: /usr/local/cvs/myproj/newfile.c,v
done
Checking in newfile.c;
/usr/local/cvs/myproj/newfile.c,v <ó newfile.c
initial revision: 1.1
done
user@linux ~$
|
|
|
Im Gegensatz zum Hinzufügen einer Datei verläuft das Hinzufügen eines
Verzeichnisses in einem Schritt; das anschließende Commit entfällt
hier:
user@linux ~$
mkdir c-subdir
user@linux ~$
$ cvs add c-subdir
Directory /usr/local/cvs/myproj/c-subdir added to the repository
user@linux ~$
|
Betrachtet man nun den Inhalt des neuen Verzeichnisses der
Arbeitskopie, so sieht man, dass durch das add-Kommando automatisch
ein CVS-Unterverzeichnis darin angelegt wurde:
user@linux ~$
ls c-subdir
CVS/
user@linux ~$
ls c-subdir/CVS
Entries Repository Root
user@linux ~$
|
Nun können, wie in jedem anderen Verzeichnis der Arbeitskopie, Dateien
(oder neue Unterverzeichnisse) angelegt werden.
CVS und Binärdateien
Bisher habe ich ein kleines schmutziges Geheimnis von CVS ausgelassen,
nämlich dass CVS Binärdateien nicht gut verwalten kann (nun, es gibt
noch andere kleine schmutzige Geheimnisse von CVS, aber dies zählt
bestimmt zu den schmutzigsten). Es ist nicht so, dass CVS Binärdateien
gar nicht behandeln könnte; es kann dies nur nicht so elegant.
Alle Dateien, mit denen wir bisher zu tun hatten, waren einfache
Textdateien. CVS benutzt einige spezielle Tricks für Textdateien. Zum
Beispiel konvertiert CVS automatisch Zeilenumbrüche, wenn zwischen
einem Unix-Archiv und Windows oder Macintosh Arbeitskopien
ausgetauscht werden. Unter Unix ist zum Beispiel üblich, nur ein
Linefeed- (LF-)Zeichen am Ende einer Zeile zu verwenden, wohingegen
Windows am Ende einer Zeile ein Carriage Return (CR) und ein Linefeed
(LF) erwartet. Daher haben die Dateien einer Arbeitskopie auf einem
Windows-Rechner die CRLF-Kombination am Ende der Zeilen, wohingegen
die Arbeitskopie des gleichen Projektes auf einem Unix-Rechner nur
die LF-Zeilenenden hat (das Archiv selbst hat nur LF-Zeilenenden).
Ein weiterer Trick ist, dass CVS spezielle Zeichenketten, auch
RCS-Schlüsselwörter genannt, in Textdateien erkennt und diese durch
Revisionsinformationen und andere nützliche Dinge ersetzt. Wenn eine
Datei beispielsweise
$Revision: 1.5 $
enthält, ersetzt CVS dies bei jedem Commit durch die Revisionsnummer,
also könnte es beispielsweise so aussehen:
$Revision: 1.5 $
CVS aktualisiert diese Zeichenkette während der Entwicklung. (Die
verschiedenen Schlüsselwörter sind in  Kapitel 6 und 10 dokumentiert.) Kapitel 6 und 10 dokumentiert.)
Diese Wortersetzung ist bei Textdateien sehr nützlich, da man dadurch
die Revisionsnummer und andere Informationen direkt beim Bearbeiten
sehen kann. Doch was passiert, wenn die Datei ein JPEG-Bild ist? Oder
ein übersetztes ausführbares Programm? In dieser Art von Dateien
könnte CVS erheblichen Schaden anrichten, wenn es einfach blind alle
Schlüsselwörter, die es findet, ersetzt. In Binärdateien können
solche Zeichenketten einfach zufällig auftauchen.
Daher muss, wenn eine Binärdatei hinzugefügt werden soll, CVS
mitgeteilt werden, sowohl die Schlüsselwortersetzung als auch die
Zeilenendenumwandlung zu unterlassen. Dies erfolgt mit der Option
-kb:
user@linux ~$
cvs add -kb filename
user@linux ~$
cvs ci -m "added blah" filename
(etc)
|
In manchen Fällen, wie bei Textdateien, die wahrscheinlich verstreute
Schlüsselwörter enthalten könnten, kann es sinnvoll sein, nur die
Schlüsselwortersetzung auszuschalten. Dies geschieht mit der Option
-ko:
user@linux ~$
cvs add -ko filename
user@linux ~$
cvs ci -m "added blah" filename
(etc)
|
(Tatsächlich wäre dieses Kapitel schon wegen des darin enthaltenen
Beispiels $Revision: 1.5 $ ein Fall für eine solche Textdatei.)
Zu bemerken ist auch, dass kein aussagekräftiger cvs diff zwischen
zwei Revisionen einer Binärdatei durchgeführt werden kann. Diff
benutzt einen textbasierten Algorithmus, der bei Binärdateien
lediglich die Aussage treffen kann, ob sich diese unterscheiden,
nicht aber worin. Zukünftige Versionen von CVS werden vielleicht einen
binären Diff unterstützen.
|
|
Eine Datei zu entfernen ist ähnlich, wie eine hinzuzufügen, bis auf
einen zusätzlichen Schritt: Die Datei muß zuerst aus der Arbeitskopie
entfernt werden:
user@linux ~$
rm newfile.c
user@linux ~$
cvs remove newfile.c
cvs remove: scheduling 'newfile.c' for removal
cvs remove: use 'cvs commit' to remove this file permanently
user@linux ~$
cvs ci -m "removed newfile.c" newfile.c
Removing newfile.c;
/usr/local/cvs/myproj/newfile.c,v <- newfile.c
new revision: delete; previous revision: 1.1
done
user@linux ~$
|
Zu beachten ist, dass bei dem zweiten und dritten Kommando newfile.c
explizit angegeben wird, obwohl dies in der Arbeitskopie gar nicht
mehr existiert. Natürlich muss man dies bei dem Commit nicht
unbedingt, solange man nichts dagegen hat, dass dann auch weitere
Dateien in den Commit einbezogen werden.
|
|
Wie schon zuvor erwähnt, stehen Verzeichnisse nicht unter der
Versionskontrolle von CVS. Stattdessen, als eine Art billiger Ersatz,
bietet es eine Reihe seltsamer Verhaltensweisen, die meistens das
Richtige ausführen. Eine dieser Seltsamkeiten ist, dass leere
Verzeichnisse besonders behandelt werden können. Soll ein Verzeichnis
aus einem Projekt entfernt werden, werden zuerst alle Dateien daraus
entfernt:
user@linux ~$
cd dir
user@linux ~$
rm file1 file2 file3
user@linux ~$
cvs remove file1 file2 file3
(Ausgabe ausgelassen)
user@linux ~$
cvs ci -m "removed all files" file1 file2 file3
(Ausgabe ausgelassen)
|
und dann in dem übergeordneten Verzeichnis update mit der -P-Option ausgeführt:
user@linux ~$
cd ..
user@linux ~$
cvs update -P
(Ausgabe ausgelassen)
|
Die -P-Option bedeutet für update, leere Verzeichnisse zu reduzieren -
diese also aus der Arbeitskopie zu entfernen. Ist dies einmal
ausgeführt, kann das Verzeichnis als gelöscht angesehen werden; alle
Dateien sind weg und das Verzeichnis selbst ebenfalls (zumindest in
der Arbeitskopie, dennoch existiert ein leeres Verzeichnis in dem
Archiv).
Ein interessantes Gegenstück zu diesem Verhalten ist, dass CVS bei
einem einfachen update keine neuen Verzeichnisse aus dem Archiv in die
Arbeitskopie einfügt. Es gibt dafür eine Reihe von Begründungen, von
denen an dieser Stelle keine besonders erwähnenswert ist. Kurz
zusammengefasst kann man sagen, dass Sie von Zeit zu Zeit update mit
der Option -p ausführen sollten, damit neue Verzeichnisse aus dem
Archiv in Ihre Arbeitskopie eingefügt werden.
|
|
Eine Datei umzubenennen ist das Gleiche, wie diese zu löschen und
unter einem neuen Namen anzulegen. Unter Unix sind die Befehle dazu:
user@linux ~$
cp oldname newname
user@linux ~$
rm oldname
|
Und hier ist das CVS-Äquivalent:
user@linux ~$
mv oldname newname
user@linux ~$
cvs remove oldname
(Ausgabe ausgelassen)
user@linux ~$
cvs add newname
(Ausgabe ausgelassen)
user@linux ~$
cvs ci -m "renamed oldname to newname" oldname newname
(Ausgabe ausgelassen)
user@linux ~$
|
Bezüglich Dateien ist das alles, was zu tun ist. Verzeichnisse
umzubenennen ist nicht sonderlich anders: das neue Verzeichnis
anlegen, cvs add ausführen, alle Dateien des alten Verzeichnisses in
das neue bewegen, cvs remove ausführen, um diese aus dem alten
Verzeichnis zu entfernen, cvs add ausführen, um diese in dem neuen
Verzeichnis hinzuzufügen, cvs commit ausführen, damit auch alles dem
Archiv mitgeteilt wird, und dann cvs update -P ausführen, damit das
nun leere Verzeichnis auch aus der Arbeitskopie verschwindet. Also:
user@linux ~$
mkdir newdir
user@linux ~$
cvs add newdir
user@linux ~$
mv olddir/* newdir
mv: newdir/CVS: cannot overwrite directory
user@linux ~$
cd olddir
user@linux ~$
cvs rm foo.c bar.txt
user@linux ~$
cd ../newdir
user@linux ~$
cvs add foo.c bar.txt
user@linux ~$
cd ..
user@linux ~$
cvs commit -m "moved foo.c and bar.txt from olddir to newdir"
user@linux ~$
cvs update -P
|
Bemerkung
Beachten Sie die Warnmeldung nach dem dritten Befehl. Diese besagt,
dass das CVS/Unterverzeichnis von olddir nicht in newdir kopiert
werden kann, da in newdir schon ein solches existiert. Dies ist
auch gut so, da man sowieso das CVS/ Unterverzeichnis in newdir
unverändert beibehalten möchte.
|
Ganz offensichtlich ist das Verschieben von Dateien etwas umständlich.
Die beste Methode ist es, schon beim ersten Import des Projektes ein
gutes Verzeichnislayout zu haben, sodass später möglichst selten
ganze Verzeichnisse verschoben werden müssen. Später werden Sie eine
etwas drastischere Methode zum Verschieben von Verzeichnissen
kennenlernen, welche die Veränderungen direkt im Archiv vornimmt.
Diese Methode sollte jedoch für Notfälle aufgehoben werden; nach
Möglichkeit sollte alles mit CVS-Operationen innerhalb der
Arbeitskopie behandelt werden.
|
|
Die meisten Benutzer sind es recht bald leid, zu jedem Befehl immer
wieder die gleichen Optionen eingeben zu müssen. Wenn man im Vorhinein
weiß, dass immer die globale Option -Q oder die Option -c im
Zusammenhang mit diff angegeben werden soll, warum sollte dies dann
immer wieder eingegeben werden müssen?
Doch dafür gibt es glücklicherweise Abhilfe. CVS überprüft dazu die
Datei .cvsrc im Home-Verzeichnis des Benutzers. In dieser Datei können
standardmäßige Optionen zu bestimmten Kommandos angegeben werden, die
immer ausgeführt werden, wenn CVS aufgerufen wird. Hier eine solche
beispielhafte Datei:
|
.cvsrc
|
diff -c
update -p
cvs -q
|
Entspricht die linke Spalte einem angegebenen CVS-Kommando (in der
nicht gekürzten Form), werden die entsprechenden Optionen jedes Mal,
wenn CVS verwendet wird, angewendet. Globale Optionen können mit cvs
angegeben werden. In diesem Beispiel wird also jedes Mal wenn diff
ausgeführt wird, die Option -c automatisch mit ausgeführt.
|
|
Gehen wir noch einmal zu dem Beispiel zurück, in dem ein Programm
gerade nicht lauffähig ist, wenn eine bestimmte Fehlerbeschreibung
eines Benutzers eintrifft und diese daher nicht überprüft werden
kann. Der Entwickler braucht dann plötzlich Zugriff auf das gesamte
Projekt in dem Zustand, in dem es war, als die letzte Version
freigegeben wurde. Viele Dateien sind seitdem verändert worden, und
die meisten Revisionsnummern unterscheiden sich. Es wäre viel zu
aufwändig, die gesamten Log-Nachrichten durchzulesen, um
herauszufinden, welche Revisionsnummer eine jede Datei zum Zeitpunkt
der letzten Freigabe einer Version hatte, um dann update (unter Angabe
einer Revisionsnummer mittels -r) auf jede Datei anzuwenden. Bei
mittleren oder großen Projekten (einige Dutzend bis zu Tausende
Dateien) wäre dies ein hoffnungsloser Versuch.
CVS bietet daher die Möglichkeit, vorangegangene Revisionen aller
Dateien auf einmal zu holen. Tatsächlich gibt es dafür zwei Methoden:
nach Datum, dies wählt die zu holende Revision basierend auf dem
Datum des Zeitpunkts ihres Commit aus, und mit Hilfe von Marken, was
eine Momentaufnahme eine Projektes holt, die durch eine Marke
gekennzeichnet wurde.
Welche der beiden Methoden zum Einsatz kommt, hängt von der Situation
ab. Das datumsbasierte Holen einer Revision wird durch die Option -D
zu update erreicht, die ähnlich zu -r ist, aber als Argument ein
Datum und nicht eine Revisionsnummer benötigt:
user@linux ~$
cvs -q update -D "1999-04-19"
U hello.c
U a-subdir/subsubdir/fish.c
U b-subdir/random.c
user@linux ~$
|
Mit der -D-Option holt update die höchste Revision einer jeden Datei
eines gegebenen Datums und überführt, wenn nötig, die Dateien der
Arbeitskopie in vorangegangene Revisionen.
Zusätzlich zu einem Datum kann, und sollte meistens auch, eine Uhrzeit
angegeben werden. Zum Beispiel endete das vorangegangene Beispiel
darin, vor allem die Revision 1.1 zu holen (nur drei der Dateien
waren verändert, da alle anderen noch Revision 1.1 hatten). Als
Beweis hier die Statusausgabe für die Datei hello.c:
user@linux ~$
cvs -Q status hello.c
==========================================
File: hello.c Status: Up-to-date
Working revision: 1.1.1.1 Sat Apr 24 22:45:03 1999
Repository revision: 1.1.1.1 /usr/local/cvs/myproj/hello.c,v
Sticky Date: 99.04.19.05.00.00
user@linux ~$
|
Ein Blick in die Log-Nachrichten zeigt jedoch, dass Revision 1.2 von
hello.c definitiv am 19. April 1999 durch einen Commit entstand. Also
warum wurde jetzt Revision 1.1 anstatt 1.2 geholt?
Das Problem ist, dass das Datum 1999-04-19 als Mitternacht
beginnend am 19.4.1999 interpretiert wurde - also der erste Zeitpunkt
dieses Tages. Das ist wahrscheinlich nicht das, was man möchte. Das
Commit der Revision 1.2 fand später an diesem Tag statt. Durch nähere
Spezifizierung des Datums kann auch Revision 1.2 geholt werden:
user@linux ~$
cvs -q update -D "1999-04-19 23:59:59"
U hello.c
U a-subdir/subsubdir/fish.c
U b-subdir/random.c
user@linux ~$
cvs status hello.c
=======================================
File: hello.c Status: Locally Modified
Working revision: 1.2 Sat Apr 24 22:45:22 1999
Repository revision: 1.2 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: (none)
Sticky Date: 99.04.20.04.59.59
Sticky Options: (none)
user@linux ~$
|
Wir sind fast am Ziel. Betrachten wir nun Datum und Uhrzeit in der
Zeile Sticky Date näher, scheint dort 4:59:59 a.m. Uhr zu stehen und
nicht 11:59 Uhr, wie es durch den Befehl angefordert wurde (wir
kommen später dazu, was sticky bedeutet). Wie Sie vielleicht schon
erraten haben, liegt dieser Unterschied in der Differenz zwischen der
lokalen Zeit und der Universal Coordinated Time (auch Greenwich Mean
Time genannt) begründet. Im Archiv werden alle Zeitstempel immer in
Universal Time gespeichert, CVS benutzt jedoch auf der Seite des
Clients die lokale Zeitzone. Im Falle von -D ist dies etwas
unglücklich, da man wahrscheinlich mit den Daten und Zeiten des
Archivs vergleichen möchte und die Systemzeit des lokalen Systems
egal ist. Dies kann umgangen werden, indem bei dem Befehlsaufruf
zusätzlich die GMT-Zeitzone angegeben wird:
user@linux ~$
cvs -q update -D "1999-04-19 23:59:59 GMT"
U hello.c
user@linux ~$
cvs -q status hello.c
============================================
File: hello.c Status: Up-to-date
Working revision: 1.2 Sun Apr 25 22:38:53 1999
Repository revision: 1.2 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: (none)
Sticky Date: 99.04.19.23.59.59
Sticky Options: (none)
user@linux ~$
|
Endlich - dies brachte nun die Arbeitskopie auf den letzten, durch
Commit erreichten Stand vom 19. April (es sei denn, es hätte noch
weitere Beiträge durch Commit in der letzten Sekunde des Tages
gegeben, was aber nicht der Fall ist).
Was passiert, wenn nun update ausgeführt wird?
user@linux ~$
cvs update
cvs update: Updating .
cvs update: Updating a-subdir
cvs update: Updating a-subdir/subsubdir
cvs update: Updating b-subdir
user@linux ~$
|
Es passiert gar nichts. Wir wissen aber, dass es aktuellere Versionen
der letzten drei Dateien gibt. Warum sind diese nicht in der
Arbeitskopie enthalten?
Genau dies ist die Bedeutung von sticky (bindend). Eine
Aktualisierung (Rückterminierung?) mit der -D-Option bewirkt, dass
die Arbeitskopie auf dieses vergangene Datum festgelegt wird. In der
Terminologie von CVS spricht man davon, dass für diese Arbeitskopie
ein bindendes Datum gesetzt wurde. Hat eine Arbeitskopie einmal eine
bindenden Eigenschaft bekommen, bleibt diese so lange erhalten, bis
sie explizit zurückgenommen wird. Daher werden nun folgende Updates
nicht mehr die aktuellste Version holen. Stattdessen bleiben diese
bei diesem bindenden Datum. Bindende Eigenschaften können mit dem cvs
status-Kommando angezeigt oder direkt in der CVS/Entries-Datei
nachgelesen werden:
user@linux ~$
cvs -q update -D "1999-04-19 23:59:59 GMT"
U hello.c
user@linux ~$
cat CVS/Entries
D/a-subdir////
D/b-subdir////
D/c-subdir////
/README.txt/1.1.1.1/Sun Apr 18 18:18:22 1999//D99.04.19.23.59.59
/hello.c/1.2/Sun Apr 25 23:07:29 1999//D99.04.19.23.59.59
user@linux ~$
|
Sollte man nun hello.c modifiziert haben und einen Commit versuchen:
user@linux ~$
cvs update
M hello.c
user@linux ~$
cvs ci -m "trying to change the past"
cvs commit: cannot commit with sticky date for file 'hello.c'
cvs [commit aborted]: correct above errors first!
user@linux ~$
|
so würde CVS das nicht zulassen, da dies so wäre, als erlaube man, in
der Zeit zurück zu reisen und die Vergangenheit zu ändern. CVS basiert
auf chronologischen Aufzeichnungen und kann dies daher nicht
zulassen.
Das bedeutet aber nicht, dass CVS auf einmal nichts mehr von allen
anderen Revisionen weiß, die seitdem per Commit eingeflossen sind. Man
kann immer noch die mit einem bindenden Datum versehene Arbeitskopie
mit anderen Revisionen vergleichen, zukünftige eingeschlossen:
user@linux ~$
cvs -q diff -c -r 1.5 hello.c
Index: hello.c
=====================================
RCS file: /usr/local/cvs/myproj/hello.c,v
retrieving revision 1.5
diff -c -r1.5 hello.c
*** hello.c 1999/04/24 22:09:27 1.5
--- hello.c 1999/04/25 00:08:44
***************
*** 3,9 ****
void
main ()
{
printf ("Hello, world!\n");
- printf ("between hello and goodbye\n");
printf ("Goodbye, world!\n");
}
--- 3,9 ----
void
main ()
{
+ /* this line was added to a downdated working copy */
printf ("Hello, world!\n");
printf ("Goodbye, world!\n");
}
|
Der Diff zeigt auf, dass, ausgehend vom 19. April 1999, die Zeile
between hello and goodbye noch nicht hinzugefügt wurde. Er zeigt
auch die Modifikation, die wir in der Arbeitskopie gemacht haben (der
in dem vorangegangenen Quelltextauszug gezeigte zusätzliche
Kommentar).
Das bindende Datum sowie alle anderen bindenden Eigenschaften können
mit der Option -A (-A steht für reset, fragen Sie mich nicht, warum)
zu update entfernt werden, was die Arbeitskopie wieder auf den
aktuellsten Stand bringt:
user@linux ~$
cvs -q update -A
U hello.c
user@linux ~$
cvs status hello.c
======================================
File: hello.c Status: Up-to-date
Working revision: 1.5 Sun Apr 25 22:50:27 1999
Repository revision: 1.5 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
user@linux ~$
|
Gültige Datumsformate
CVS akzeptiert eine breite Auswahl an Datumsformaten. Mit dem ISO
8691-Format liegt man nie falsch (also Standard #8601 der
International Standards Organization, siehe auch
 www.saqqara.demon.co.uk/datefmt.htm), das auch in den vorangegangenen
Beispielen verwendet wurde. Es können auch die E-Mail-Formate für
Datum und Uhrzeit verwendet werden, die in RFC 822 und RFC 1123 (siehe
www.rfc-editor.org/rfc/) beschrieben sind. Letztendlich können
eindeutige Konstruktionen der englischen Datumsformate verwendet
werden, um Daten relativ zum aktuellen Datum zu beschreiben. www.saqqara.demon.co.uk/datefmt.htm), das auch in den vorangegangenen
Beispielen verwendet wurde. Es können auch die E-Mail-Formate für
Datum und Uhrzeit verwendet werden, die in RFC 822 und RFC 1123 (siehe
www.rfc-editor.org/rfc/) beschrieben sind. Letztendlich können
eindeutige Konstruktionen der englischen Datumsformate verwendet
werden, um Daten relativ zum aktuellen Datum zu beschreiben.
Sie werden sicherlich nicht alle möglichen Formate benötigen, dennoch
hier noch ein paar Beispiele, um Ihnen eine Vorstellung davon zu
geben, welche Formate CVS akzeptiert:
user@linux ~$
cvs update -D "19 Apr 1999"
user@linux ~$
cvs update -D "19 Apr 1999 20:05"
user@linux ~$
cvs update -D "19/04/1999"
user@linux ~$
cvs update -D "3 days ago"
user@linux ~$
cvs update -D "5 years ago"
user@linux ~$
cvs update -D "19 Apr 1999 23:59:59 GMT"
user@linux ~$
cvs update -D "19 Apr"
|
Die Anführungszeichen dienen lediglich dazu, der Unix-Shell
mitzuteilen, dass es sich jeweils um ein Argument handelt, obwohl
Leerzeichen enthalten sind. Die Anführungszeichen stören auch dann
nicht, wenn das Datum keine Leerzeichen enthält. Daher ist es
sinnvoll, immer welche zu verwenden.
Einen Zeitpunkt markieren (Marken)
Mittels eines Datums Dateien wieder zu holen ist nützlich, wenn
lediglich der zeitliche Verlauf von hauptsächlichem Interesse ist.
Öfter jedoch soll ein Projekt wieder in einen Zustand gebracht
werden, in dem es zu einem bestimmten Ereignis war, beispielsweise dem
Zeitpunkt einer Veröffentlichung einer bekanntermaßen stabilen
Version oder dem Zeitpunkt, zu dem größere Teile hinzugefügt oder
weggenommen wurden.
Sich diese speziellen Daten einfach zu merken oder diese anhand der
Log-Dateien wiederzufinden, wäre ein langwieriger und schwieriger
Prozess. Vermutlich wurde ein solcher Zeitpunkt, weil er wichtig war,
in der Revisionshistorie markiert. CVS bietet dazu das Markieren
(engl. tagging) an.
Markierungen unterscheiden sich von einem normalen Commit, indem keine
Veränderungen an den Quelltexten an sich gespeichert werden, sondern
lediglich eine Veränderung der Einschätzung der Dateien durch den
Entwickler. Eine Markierung zeichnet eine Gruppe von Revisionen,
repräsentiert durch die Arbeitskopie eines Entwicklers, besonders aus
(für gewöhnlich ist dabei diese Arbeitskopie vollständig aktuell,
sodass der Name dieser Markierung der letzten und höchsten Revision
des Archivs hinzugefügt wird).
Eine Markierung zu setzen ist einfach:
user@linux ~$
cvs -q tag Release-1999_05_01
T README.txt
T hello.c
T a-subdir/whatever.c
T a-subdir/subsubdir/fish.c
T b-subdir/random.c
user@linux ~$
|
Dieser Befehl verbindet den symbolischen Namen Release-1999_05_01
mit der Momentaufnahme, die durch die aktuelle Arbeitskopie
repräsentiert wird. Formell definiert bezeichnet eine Momentaufnahme
eine Gruppe von Dateien und ihre Revisionsnummern innerhalb des
Projektes. Diese Revisionsnummern müssen nicht in allen Dateien
gleich sein, was sie für gewöhnlich auch nicht sind. Wäre zum
Beispiel eine Markierung in dem Beispielprojekt, das wir in diesem
ganzen Kapitel verwendet haben, gesetzt worden und die Arbeitskopie
wäre auf dem letzten Stand, dann wäre der symbolische Name
Release-1999_05_01 zu hello.c mit Revision 1.5, fish.c mit Revision
1.2, random.c mit Revision 1.2 und allen anderen mit Revision 1.1
hinzugefügt worden.
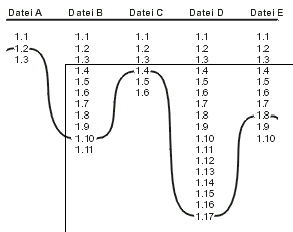 |
Bild Kap_02-1.png
|
Wie eine Markierung in Relation zur Revisionshistorie eines Projektes
stehen kann.
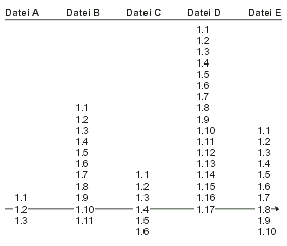 |
Bild Kap_02-2.png
|
Eine Markierung ist eine Gerade Aussicht durch die Revisionshistorie.
Vielleicht ist es hilfreich, sich eine Markierung als einen Pfad oder
eine Schnur vorzustellen, welche die verschiedenen Revisionen der
Dateien miteinander verbindet.
Wird die Schnur gerade gezogen und sieht man direkt an ihr entlang, so
sieht man einen bestimmten Moment aus der Projektgeschichte - nämlich
genau den Moment, zu dem die Markierung gesetzt wurde (Abbildung
2.2).
Werden nun weiter Dateien verändert und die Veränderung durch einen
Commit dem Archiv zur Verfügung gestellt, so wird die Markierung nicht
mit den wachsenden Revisionsnummern mit bewegt. Diese bleibt fest,
gebunden zu der Revisionsnummer einer jeden Datei, zu der diese
Markierung gesetzt wurde.
Durch ihre erläuternde Bedeutung ist es etwas unglücklich, dass
Markierungen keine langen Nachrichten oder ganze Paragraphen mit
Fließtext enthalten können. In dem vorangegangenen Beispiel besagte
die Markierung einfach und offensichtlich, dass sich das Projekt zu
diesem Datum in einem zu veröffentlichenden Zustand befand.
Manchmal möchte man jedoch komplexere Zustände markieren, was in sehr
unvorteilhaften Markierungen mündet:
user@linux ~$
cvs tag testing-release-3_pre-19990525-public-release
|
Als allgemeine Regel sollte gelten, Markierungsnamen so knapp wie
möglich zu halten, aber trotzdem alle notwendigen Informationen über
das spezielle Ereignis, das aufgezeichnet werden soll, zu enthalten.
Seien Sie im Zweifelsfall lieber zu ausführlich - Sie werden es sich
später selbst danken, wenn Sie anhand eines Markierungsnamens exakt
aussagen können, was denn genau aufgezeichnet wurde (oder werden
sollte).
Ihnen ist vielleicht schon aufgefallen, dass keine Punkte oder
Leerzeichen in den Markierungsnamen enthalten waren. CVS ist in der
Bewertung, was einen gültigen Markierungsnamen darstellt, ziemlich
streng. Die Regeln besagen, dass dieser mit einem Buchstaben beginnen
muss und Buchstaben, Ziffern, Bindestriche (-) und Unterstriche
(_) enthalten darf. Es dürfen keine Leerzeichen, Punkte,
Doppelpunkte, Kommas oder andere Symbole verwendet werden.
Um eine Momentaufnahme mittels eines Markierungsnamens aus dem Archiv
zu holen, wird dieser wie eine Revisionsnummer benutzt. Es gibt zwei
Möglichkeiten, eine Momentaufnahme zu bekommen: Man kann eine
neue Arbeitskopie mit einer bestimmten Markierung auschecken
(Checkout), oder man kann eine existierende Arbeitskopie mit Hilfe der
Markierung dahin überführen. Beide Wege führen zu einer Arbeitskopie,
deren Dateien den Revisionen entsprechen, die durch die Markierung
spezifiziert wurden.
Meistens wird man versuchen, einen Blick in das Projekt in dem Zustand
zu werfen, in dem es zum Zeitpunkt der Markierung war. Dies wird man
nicht notwendigerweise mit seiner Hauptarbeitskopie machen wollen,
die wahrscheinlich noch nicht per commit abgeschickte Veränderungen
enthält. Nehmen wir also an, es soll eine separate Arbeitskopie per
Checkout unter Verwendung der Markierung geholt werden. Dies
geschieht folgendermaßen (stellen Sie jedoch sicher, dass Sie dies
irgendwo anders als in Ihrer existierenden Arbeitskopie oder dem
darüber liegenden Verzeichnis ausführen!):
user@linux ~$
cvs checkout -r Release-1999_05_01 myproj
cvs checkout: Updating myproj
U myproj/README.txt
U myproj/hello.c
cvs checkout: Updating myproj/a-subdir
U myproj/a-subdir/whatever.c
cvs checkout: Updating myproj/a-subdir/subsubdir
U myproj/a-subdir/subsubdir/fish.c
cvs checkout: Updating myproj/b-subdir
U myproj/b-subdir/random.c
cvs checkout: Updating myproj/c-subdir
|
Die -r-Option wurde bereits für das update-Kommando verwendet und
spezifizierte dort eine Revisionsnummer. Eine Markierung verhält sich
in vielen Belangen wie eine Revisionsnummer, da eine bestimmte
Markierung für eine bestimmte Datei genau einer Revisionsnummer
entspricht. (Es ist grundsätzlich nicht möglich, zwei gleich lautende
Markierungen innerhalb eines Projektes zu verwenden.) Tatsächlich kann
man überall dort, wo auch eine Revisionsnummer benutzt werden kann,
einen Markierungsnamen als Teil eines CVS-Befehls verwenden
(vorausgesetzt, die Markierung wurde vorher gesetzt). Soll ein Diff
des aktuellen Zustands einer Datei relativ zu einem Zustand einer
veröffentlichten Version gemacht werden, kann dies so erfolgen:
user@linux ~$
cvs diff -c -r Release-1999_05_01 hello.c
|
Und wenn vorübergehend zu dieser Revision zurückgegangen werden soll,
geht dies so:
user@linux ~$
cvs update -r Release-1999_05_01 hello.c
|
Die Austauschbarkeit von Revisionsnummern mit Markierungen ist ein
Grund für die strengen Regeln der zulässigen Namen. Stellen Sie sich
einmal vor, dass Punkte in den Namen erlaubt wären; es könnte dann
eine Markierung geben, die 1.3 heißt und zu einer tatsächlichen
Revisionsnummer 1.47 gehören soll. Würde dann Folgendes ausgeführt
user@linux ~$
cvs update -r 1.3 hello.c
|
wie sollte CVS dann wissen, ob sich dies nun auf die Markierung 1.3
oder die viel frühere Revision 1.3 von hello.c bezieht? Daher werden
die Markierungsnamen derart eingeschränkt und können so einfach von
Revisionsnummern unterschieden werden. Eine Revisionsnummer hat einen
Punkt, eine Markierung nicht. (Es gibt auch für die anderen
Einschränkungen Gründe, und die meisten haben damit zu tun, dass
dadurch die Markierungsnamen für CVS einfacher zu lesen sind.)
Wie Sie sich sicherlich haben denken können, besteht die zweite
Methode, eine Momentaufnahme zu bekommen - also eine bestehende
Arbeitskopie in die markierte Revision zu überführen - ebenfalls
darin, update auszuführen:
user@linux ~$
cvs update -r Release-1999_05_01
cvs update: Updating .
cvs update: Updating a-subdir
cvs update: Updating a-subdir/subsubdir
cvs update: Updating b-subdir
cvs update: Updating c-subdir
user@linux ~$
|
Der vorangegangene Befehl ist der gleiche wie der, der verwendet
wurde, um hello.c zu Release-1999_05_01 zurückzuführen, bis darauf, dass
der Dateiname ausgelassen wurde, da das gesamte Projekt zurückgeführt
werden soll. (Sie können auch, wenn Sie dies wollen, nur einen Zweig
der Verzeichnisstruktur des Projektes zurückführen, indem der
vorangegangene Befehl in dem entsprechenden Unterverzeichnis anstatt
im Hauptverzeichnis ausgeführt wird, obwohl Sie dies wohl nie richtig
wollen werden.)
Beachten Sie, dass anscheinend bei dem Update keine Dateien verändert
wurden. Die Arbeitskopie war völlig aktuell, als die Marke gesetzt
wurde, und es wurden seitdem keine Veränderungen vorgenommen.
Dies bedeutet jedoch nicht, dass sich gar nichts verändert hat. Die
Arbeitskopie ist nun markiert. Wird nun eine Veränderung gemacht und
versucht, diese mit commit an das Archiv zu schicken (nehmen wir an,
es wurde hello.c verändert):
user@linux ~$
cvs -q update
M hello.c
user@linux ~$
cvs -q ci -m "trying to commit from a working copy on a tag"
cvs commit: sticky tag 'Release-1999_05_01' for file 'hello.c' is not
a branch
cvs [commit aborted]: correct above errors first!
user@linux ~$
|
so lässt CVS dies nicht zu. (Kümmern Sie sich erst einmal nicht um die
genaue Bedeutung obiger Fehlermeldung - wir werden Verzweigungen als
Nächstes in diesem Kapitel behandeln). Es spielt dabei keine Rolle,
ob die Markierung aus einem Checkout oder Update resultiert. Ist diese
einmal markiert, sieht CVS die Arbeitskopie als eine statische
Momentaufnahme der Vergangenheit an und erlaubt Ihnen nicht mehr, die
Vergangenheit zu ändern, zumindest nicht so einfach. Wird cvs status
ausgeführt oder wenn Sie sich die CVS/Entries-Datei ansehen, werden
Sie feststellen, dass für jede Datei eine bindende Markierung
(sticky tag) gesetzt ist. Zum Beispiel ist dies die
Haupt-Entries-Datei:
user@linux ~$
cat CVS/Entries
D/a-subdir////
D/b-subdir////
D/c-subdir////
/README.txt/1.1.1.1/Sun Apr 18 18:18:22 1999//TRelease-1999_05_01
/hello.c/1.5/Tue Apr 20 07:24:10 1999//TRelease-1999_05_01
user@linux ~$
|
Markierungen werden genau wie andere bindende Eigenschaften mit der
-A-Option von update entfernt:
user@linux ~$
cvs -q update -A
M hello.c
user@linux ~$
|
Die Veränderungen an hello.c gehen jedoch nicht verloren; CVS erkennt
immer noch, dass die Datei bezüglich des Archivs verändert wurde:
user@linux ~$
cvs -q diff -c hello.c
Index: hello.c
===========================================
RCS file: /usr/local/cvs/myproj/hello.c,v
retrieving revision 1.5
diff -c -r1.5 hello.c
*** hello.c 1999/04/20 06:12:56 1.5
--- hello.c 1999/05/04 20:09:17
***************
*** 6,9 ****
--- 6,10 ----
printf ("Hello, world!\n");
printf ("between hello and goodbye\n");
printf ("Goodbye, world!\n");
+ /* a comment on the last line */
}
user@linux ~$
|
Nun, da durch update alle bindenden Eigenschaften entfernt wurden,
akzeptiert CVS auch wieder einen Commit:
user@linux ~$
cvs ci -m "added comment to end of main function"
cvs commit: Examining .
cvs commit: Examining a-subdir
cvs commit: Examining a-subdir/subsubdir
cvs commit: Examining b-subdir
cvs commit: Examining c-subdir
Checking in hello.c;
/usr/local/cvs/myproj/hello.c,v <- hello.c
new revision: 1.6; previous revision: 1.5
done
user@linux ~$
|
Die Markierung Release-1999_05_01 gehört selbstverständlich immer
noch zu Revision 1.5. Vergleichen Sie den Status der Datei vor und
nach dieser Umkehrung zu dieser Markierung:
user@linux ~$
cvs -q status hello.c
==============================================
File: hello.c Status: Up-to-date
Working revision: 1.6 Tue May 4 20:09:17 1999
Repository revision: 1.6 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: (none)
Sticky Date: (none)
Sticky Options: (none)
user@linux ~$
cvs -q update -r Release-1999_05_01
U hello.c
user@linux ~$
cvs -q status hello.c
==============================================
File: hello.c Status: Up-to-date
Working revision: 1.5 Tue May 4 20:21:12 1999
Repository revision: 1.5 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: Release-1999_05_01 (revision: 1.5)
Sticky Date: (none)
Sticky Options: (none)
user@linux ~$
|
Nun, da ich Ihnen gesagt habe, dass CVS Sie die Geschichte nicht
verändern lässt, zeige ich Ihnen, wie Sie die Geschichte verändern können.
|
|
Bisher wurde CVS als eine intelligente und koordinierende Bibliothek
betrachtet. Man kann sich CVS aber auch als eine Zeitmaschine
vorstellen (Danke schön an Jim Blandy für diese Analogie). Bisher
haben wir nur gesehen, wie die Vergangenheit mit CVS betrachtet werden
kann, ohne darauf irgendeinen Einfluss zu nehmen. Doch wie alle guten
Zeitmaschinen erlaubt CVS jedoch auch in der Zeit zurückzugehen und
die Vergangenheit zu verändern. Was ist das Resultat daraus? Wie jeder
Science Fiction-Fan weiß, ist die Antwort darauf: ein weiteres
Universum, parallel zu unserem, aber genau an dem Punkt divergierend,
an dem die Vergangenheit verändert wurde. Eine Verzweigung im Sinne
von CVS spaltet die Entwicklung eines Projektes in getrennte,
parallele Historien. Veränderungen in einem Zweig betreffen den
anderen nicht mehr.
Warum ist dies nützlich?
Kehren wir für einen Moment noch einmal zu dem Szenario zurück, in dem
ein Entwickler, mitten in der Entwicklung einer neuen Version eines
Programmes, eine Fehlerbeschreibung über eine ältere Version bekommt.
Angenommen, der Entwickler behebt das Problem, so muss er diese
Korrektur immer noch dem Kunden zukommen lassen. Es ist sicherlich
nicht sonderlich hilfreich, eine ältere Kopie ausfindig zu machen,
darin den Fehler zu beheben, ohne dies CVS wissen zu lassen, und das
Ganze dem Kunden zu schicken. Es gäbe anschließend keinerlei
Aufzeichnung der durchgeführten Änderung; CVS hätte keine
Informationen darüber; und wenn später festgestellt würde, dass auch
die Fehlerbehebung einen Fehler hat, hätte niemand einen Ansatzpunkt,
um das Problem zu reproduzieren
Noch schlimmer wäre es, den Fehler in der aktuellen und instabilen
Version der Quelltexte zu beheben und dies dem Kunden zu schicken.
Sicherlich könnte der Fehler behoben sein, doch der Rest des
Quelltextes ist in einem instabilen und noch nicht getesteten Zustand.
Sie könnte laufen, aber sie ist sicherlich noch nicht
produktionsreif.
Weil die letzte veröffentlichte Version, von eben dem einen Fehler
abgesehen, als stabil angesehen wird, ist die beste Lösung
zurückzugehen und den Fehler in dieser älteren Version zu beheben -
also ein weiteres Universum zu schaffen, in dem die letzte
veröffentlichte Version die Fehlerbeseitigung beinhaltet.
Dies ist der Punkt, an dem Verzweigungen ins Spiel kommen. Der
Entwickler spaltet einen Zweig ab, der in der Hauptentwicklungslinie
(engl. trunk) verwurzelt ist, aber nicht mit den aktuellen
Revisionen, sondern zurück zu dem Zeitpunkt der letzten
Veröffentlichung. Dann kann er einen Checkout einer Arbeitskopie
dieses Zweiges machen, die zur Fehlerbeseitigung notwendigen
Veränderungen anbringen und diese durch einen Commit wieder CVS
mitteilen, sodass davon Aufzeichnungen existieren. Nun kann er eine
Zwischenversion zusammenstellen, die auf diesem Zweig basiert, und
diese an den Kunden ausliefern.
Seine Veränderungen beeinflussen die Quelltexte der
Hauptentwicklungslinie nicht, was er auch sicherlich nicht wollte,
ohne sich vorher zu vergewissern, dass diese die gleiche Art von
Fehlerbereinigung benötigen. Sollte dies aber doch der Fall sein, kann
er die Veränderungen des Zweiges wieder in die Hauptentwicklungslinie
integrieren (merge). Bei einem Merge bestimmt CVS die
Veränderungen, die seit dem Zeitpunkt der Aufspaltung von der
Hauptentwicklungslinie bis zu der aktuellen Spitze (der aktuellste
Stand des Zweiges) stattgefunden haben, und bringt diese Veränderung
an dem Projekt zum Stand der Spitze des Zweiges an. Der Unterschied
zwischen der Wurzel des Zweiges und der Spitze stellt sich,
natürlich, als eben die Bereinigung des Fehlers heraus.
Ein Merge kann auch als ein Spezialfall des update angesehen werden.
Der Unterschied beim Merge ist, dass die wieder zu integrierenden
Veränderungen von Wurzel und Spitze des Zweiges abgeleitet werden und
nicht durch den Vergleich einer Arbeitskopie mit dem Archiv.
Der Akt des Update an sich ist ähnlich wie die Patches von den
jeweiligen Autoren direkt zu bekommen und diese per Hand einzufügen.
Tatsächlich bestimmt CVS, um update durchzuführen, den Unterschied
(also wie mit dem diff-Programm selbst) zwischen der Arbeitskopie und
dem Archiv und wendet diesen Diff auf die Arbeitskopie genau so an,
wie es auch das patch-Kommando machen würde. Dieses spiegelt die Art
und Weise wieder, in der ein Entwickler Veränderungen von außerhalb
annimmt, nämlich manuell die von den anderen Autoren erhaltenen
patch-Dateien einzufügen.
Daher ist das Zusammenführen des Zweiges mit der Fehlerbereinigung mit
der Hauptentwicklungslinie wie das Einfügen eines
Fehlerbereinigungs-Patches von Dritten außerhalb des Projektes. Ein
solcher Dritter würde den Patch gegen die letzte veröffentlichte
Version machen, genau wie die Veränderungen des Zweiges gegen diese
Version gemacht werden. Wenn sich dieser Bereich der Quelltexte seit
der letzten Veröffentlichung nicht stark verändert hat, wird das
Zusammenführen ohne Probleme ablaufen. Wenn sich der Quelltext jedoch
in einem substanziell anderen Zustand befindet, wird die
Zusammenführung mit Konflikten fehlschlagen (der Patch wird also
zurückgewiesen), und man wird per Hand daran herumfummeln müssen.
Üblicherweise wird dann die betreffende Stelle gelesen, die
notwendigen Veränderungen werden per Hand eingefügt und ein Commit
ausgeführt. Abbildung 2.3 zeigt das Vorgehen bei einer Verzweigung
und Zusammenführung.
Wir werden nun die notwendigen Schritte, um das in der Abbildung
Gezeigte zu erreichen, durchgehen. Denken Sie daran, dass von links
nach rechts betrachtet nicht die Zeit voranschreitet, sondern dies
vielmehr die Revisionshistorie widerspiegelt. Die Verzweigung fand
nicht zum Zeitpunkt der Veröffentlichung statt, sondern wurde nur
etwas später dort angesetzt.
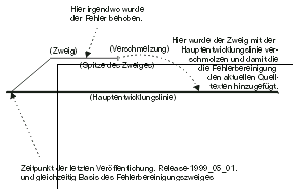 |
Kap_02-3.png
|
Verzweigung und Zusammenführung
Nehmen wir für unseren Fall an, dass die Dateien vielen Veränderungen
unterworfen waren, bis sie als Release-1999-05-01 markiert, wurden
und sogar einige hinzugekommen sind. Als die Fehlerbeschreibung über
die alte veröffentlichte Version hereinkommt, wird das Erste, was wir
machen wollen, folgendes sein: einen Zweig zu erzeugen, der auf diesem
Veröffentlichungsstand basiert und den wir praktischerweise mit
Release-1999-05-01 markieren.
Ein Weg, dies zu erreichen ist, eine Arbeitskopie basierend auf dieser
Markierung per checkout zu holen und diese mit der -b-Option erneut zu
markieren:
user@linux ~$
cd ..
user@linux ~$
ls
myproj/
user@linux ~$
cvs -q checkout -d myproj_old_release -r Release-1999_05_01 myproj
U myproj_old_release/README.txt
U myproj_old_release/hello.c
U myproj_old_release/a-subdir/whatever.c
U myproj_old_release/a-subdir/subsubdir/fish.c
U myproj_old_release/b-subdir/random.c
user@linux ~$
ls
myproj_old_release/
user@linux ~$
cd myproj_old_release
user@linux ~$
ls
CVS/ README.txt a-subdir/ b-subdir/ hello.c
user@linux ~$
cvs -q tag -b Release-1999_05_01-bugfixes
T README.txt
T hello.c
T a-subdir/whatever.c
T a-subdir/subsubdir/fish.c
T b-subdir/random.c
user@linux ~$
|
Sehen Sie sich das letzte Kommando gut an. Es mag etwas willkürlich
erscheinen, tag zur Erzeugung eines Zweiges zu verwenden, doch es gibt
einen Grund dafür: Der Markierungsname wird als eine Bezeichnung
verwendet, anhand derer der Zweig später aus dem Archiv geholt werden
kann. Zweigmarkierungen unterscheiden sich nicht von
Nicht-Zweigmarkierungen und unterliegen damit den gleichen
Restriktionen für die Namensvergabe. Manche Benutzer fügen das Wort
branch (engl. Zweig) in den Markierungsnamen ein (zum Beispiel
Release-1999_05_01-bugfix-branch), sodass die Zweigmarkierungen
leichter von anderen Markierungen unterschieden werden können.
Vielleicht möchten Sie dies auch, wenn Sie des öfteren die falsche
Markierung holen.
(Und wo wir gerade dabei sind, beachten Sie die -d
myproj_old_release-Option des checkout-Befehls beim ersten CVS-Aufruf.
Diese sagt checkout, die Arbeitskopie in das Verzeichnis namens
myproj_old_release abzulegen, damit wir diese nicht mit der aktuellen
Version in myproj durcheinander bringen. Achten Sie darauf, diese
Verwendung von -d nicht mit der globalen Option gleichen Namens oder
der -d-Option von update zu verwechseln.)
Natürlich macht die Ausführung dieses tag-Kommandos die aktuelle
Arbeitskopie nicht automatisch zu einem Zweig. Das Markieren betrifft
nie die Arbeitskopie; es zeichnet lediglich einige zusätzliche
Informationen im Archiv auf, damit diese Revision der Arbeitskopie
später wieder geholt werden kann (als ein fester Punkt in der
Geschichte oder als ein Zweig, wie es der Fall sein kann).
Das Holen kann auf zwei Wegen erfolgen (Sie werden sich vielleicht
schon daran gewöhnt haben!). Es kann aus diesem Zweig eine neue
Arbeitskopie per checkout geholt werden:
user@linux ~$
pwd
/home/whatever
user@linux ~$
cvs co -d myproj_branch -r Release-1999_05_01-bugfixes myproj
|
oder eine bereits existierende Arbeitskopie kann dazu gemacht werden:
user@linux ~$
pwd
/home/whatever/myproj
user@linux ~$
cvs update -r Release-1999_05_01-bugfixes
|
Das Resultat ist das gleiche (nun ja, der Name des übergeordneten
Verzeichnisses der neuen Arbeitskopie kann unterschiedlich sein, doch
dies ist für die Zwecke von CVS unwichtig). Sollte Ihre Arbeitskopie
noch nicht durch commit abgeschickte Veränderungen beinhalten, sollten
Sie für den Zugriff auf den Zweig besser checkout anstatt update
verwenden. Sonst würde CVS versuchen, Ihre Änderungen in die
Arbeitskopie einfließen zu lassen, während es diese zu einem Zweig
macht. In diesem Fall könnten Konflikte auftreten, auch wenn nicht,
wäre das Ergebnis ein unreiner Zweig. Dieser würde nicht dem
tatsächlichen Zustand des Programmes mit der angegebenen Markierung
entsprechen, da einige Dateien der Arbeitskopie Ihre Veränderungen
beinhalten würden.
Wie auch immer, nehmen wir an, dass Sie auf die eine oder andere Weise
eine Arbeitskopie des gewünschten Zweiges bekommen haben:
user@linux ~$
cvs -q status hello.c
===================================================
File: hello.c Status: Up-to-date
Working revision: 1.5 Tue Apr 20 06:12:56 1999
Repository revision: 1.5 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: Release-1999_05_01-bugfixes
(branch: 1.5.2)
Sticky Date: (none)
Sticky Options: (none)
user@linux ~$
cvs -q status b-subdir/random.c
==================================================
File: random.c Status: Up-to-date
Working revision: 1.2 Mon Apr 19 06:35:27 1999
Repository revision: 1.2 /usr/local/cvs/myproj/b-subdir/random.c,v
Sticky Tag: Release-1999_05_01-bugfixes (branch: 1.2.2)
Sticky Date: (none)
Sticky Options: (none)
user@linux ~$
|
(Der Inhalt der Sticky Tag-Zeilen wird gleich erläutert.) Wenn Sie nun
random.c und hello.c modifizieren und commit ausführen
user@linux ~$
cvs -q update
M hello.c
M b-subdir/random.c
user@linux ~$
cvs ci -m "fixed old punctuation bugs"
cvs commit: Examining .
cvs commit: Examining a-subdir
cvs commit: Examining a-subdir/subsubdir
cvs commit: Examining b-subdir
Checking in hello.c;
/usr/local/cvs/myproj/hello.c,v <ó hello.c
new revision: 1.5.2.1; previous revision: 1.5
done
Checking in b-subdir/random.c;
/usr/local/cvs/myproj/b-subdir/random.c,v <ó random.c
new revision: 1.2.2.1; previous revision: 1.2
done
user@linux ~$
|
werden Sie feststellen, dass etwas Lustiges mit den Revisionsnummern
vor sich geht:
user@linux ~$
cvs -q status hello.c b-subdir/random.c
===================================================
File: hello.c Status: Up-to-date
Working revision: 1.5.2.1 Wed May 5 00:13:58 1999
Repository revision: 1.5.2.1 /usr/local/cvs/myproj/hello.c,v
Sticky Tag: Release-1999_05_01-bugfixes (branch: 1.5.2)
Sticky Date: (none)
Sticky Options: (none)
===================================================
File: random.c Status: Up-to-date
Working revision: 1.2.2.1 Wed May 5 00:14:25 1999
Repository revision: 1.2.2.1 /usr/local/cvs/myproj/b-subdir/random.c,v
Sticky Tag: Release-1999_05_01-bugfixes (branch: 1.2.2)
Sticky Date: (none)
Sticky Options: (none)
user@linux ~$
|
Diese haben nun vier Ziffern anstatt zwei!
Ein näherer Blick zeigt, dass die Revisionsnummer jeder Datei
lediglich aus der Zweignummer (wie in der Sticky Tag-Zeile angegeben)
und einer extra Ziffer am Ende besteht.
Was Sie hier sehen, ist ein Stück von CVS innerer Arbeitsweise. Obwohl
Sie sicherlich immer eine Verzweigung benutzen werden, um eine
projektweite Aufspaltung zu markieren, zeichnet CVS dies jedoch auf
Basis der einzelnen Dateien auf. Dieses Projekt beinhaltete zum
Zeitpunkt der Verzweigung fünf Dateien, und es wurden daher fünf
individuelle Zweige erzeugt, alle mit dem gleichen Markierungsnamen:
Release-1999_05_01-bugfixes.
Bemerkung
Die meisten Benutzer sehen dies als eine eher unelegante
Implementierung seitens CVS an. Hier scheint ein Teil des alten
RCS-Vermächtnisses durch - RCS konnte Dateien nicht in Projekte
gruppieren, und obwohl CVS dies nun kann, benutzt CVS dennoch
Programmteile zur Verwaltung der Verzweigungen, die von RCS geerbt
wurden.
|
Für gewöhnlich brauchen Sie sich nicht darum zu kümmern, wie CVS
intern arbeitet, doch in diesem Fall ist es hilfreich zu wissen, in
welcher Beziehung Zweignummern und Revisionsnummern stehen.
Betrachten wir hello.c; alles, was ich über hello.c aussagen werde,
trifft ebenso auf die anderen Dateien des Zweiges zu
(Revisions-/Zweignummern entsprechend angepasst).
Zu dem Zeitpunkt, auf dem der Zweig basiert, hatte hello.c Revision
1.5. Als der Zweig geschaffen wurde, wurde an das Ende eine neue
Ziffer angehängt, um die Zweignummer zu bilden (CVS verwendet dazu
die noch nicht benutzte erste, gerade, ganze Zahl, die nicht null
ist). Daher wurde die Zweignummer in diesem Fall 1.5.2. Die
Zweignummer an sich ist keine Revisionsnummer, sie ist aber die Wurzel
(also das Präfix) aller weiteren Revisionsnummern von hello.c
innerhalb dieses Zweiges.
Als jedoch das erste Mal der CVS-Status der verzweigten Arbeitskopie
abgefragt wurde, wurde als Revisionsnummer nur 1.5 anstatt 1.5.2.0
oder etwas Ähnlichem angezeigt. Dies liegt daran, dass die erste
Revisionsnummer innerhalb eines Zweiges immer gleich mit der Revision
der Datei in der Hauptentwicklungslinie ist, von welcher der Zweig
stammt. Daher zeigt CVS in Statusberichten die Revisionsnummer der
Datei in der Hauptentwicklungslinie an, solange die Dateien des
Zweiges und der Hauptentwicklungslinie identisch sind.
Als eine neue Revision per commit an das Archiv übertragen wurde, war
hello.c in dem Zweig nicht mehr identisch mit der
Hauptentwicklungslinie - der Inhalt der Datei im Zweig wurde
verändert, wohingegen der der Hauptentwicklungslinie identisch blieb.
Dementsprechend wurde hello.c seine erste Zweigrevisionsnummer
zugeordnet. Dies ist in der Statusausgabe nach dem commit-Kommando zu
sehen, die nun die Revisionsnummer 1.5.2.1 zeigt.
Das Gleiche gilt auch für die Datei random.c. Deren Revisionsnummer
war zum Zeitpunkt der Verzweigung 1.2, damit ist dessen erste
Verzweigung 1.2.2. Der erste Commit von random.c innerhalb dieses
Zweiges bekam die Revisionsnummer 1.2.2.1.
Es gibt keinen numerischen Zusammenhang zwischen 1.5.2.1 und
1.2.2.1 - betrachtet man nur diese Revisionsnummern, gibt es keinen
Grund anzunehmen, dass diese Teil der gleichen Verzweigung sind, bis
auf dass beide Dateien mit Release-1999_05_01-bugfixes markiert sind
und diese Markierung zu Verzweigungsnummer 1.5.2 und 1.2.2 der
jeweiligen Dateien gehört. Daher ist der Markierungsname die einzige
Möglichkeit, den Zweig projektweit zu identifizieren. Obwohl es
absolut möglich ist, eine Datei in einen Zweig anhand ihrer
Revisionsnummer zu verschieben
user@linux ~$
cvs update -r 1.5.2.1 hello.c
U hello.c
user@linux ~$
|
ist davon fast immer abzuraten. Man würde dadurch die verzweigten
Revisionen einer Datei mit den nicht verzweigten Revisionen anderer
vermischen. Wer weiß, welche Verluste daraus entstehen? Es ist
besser, die Zweigmarkierung zur Referenz auf den Zweig zu verwenden
und alle Dateien auf einmal zu bearbeiten, als eine bestimmte Datei
zu spezifizieren. Auf diese Weise braucht man die tatsächliche
Zweigrevisionsnummer einer Datei gar nicht zu wissen oder sich darum
zu kümmern.
Es ist auch möglich, dass Zweige sich wieder verzweigen bis zu jeder
beliebig absurden Stufe. Eine Datei mit der Revisionsnummer
1.5.4.37.2.3.12.1 wird in Abbildung 2.4 grafisch dargestellt.
Zugegeben sind Umstände, in denen eine solche Verzweigungstiefe
notwendig ist, nur schwer vorstellbar, doch ist es nicht schön zu
wissen, dass CVS so weit gehen kann, wie man dies selbst möchte?
Eingebettete Verzweigungen werden genau wie jeder andere Zweig
angelegt: Eine Arbeitskopie eines Zweiges N per Checkout holen, cvs
tag -b Zweigname darin ausführen und damit Zweig N.M im Archiv
erstellen (wobei N die zugehörige Zweigrevisionsnummer jeder Datei
ist, wie beispielsweise 1.5.2.1, und M den nächstmöglichen Zweig
am Ende dieser Zahl angibt, wie beispielsweise 2).
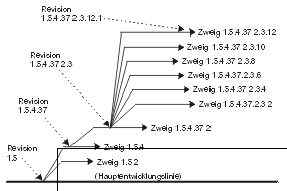 |
Kap_02-4.png
|
Ein absurd hochgradiger Verzweigungsgrad
Veränderungen zwischen Zweig und Stamm verschmelzen
Nun, da die Fehlerbereinigung durch commit in den Zweig kam, lassen
Sie uns aus der Arbeitskopie die höchste Revision der
Hauptentwicklungslinie machen und nachsehen, ob diese
Fehlerbereinigung dort auch angebracht werden muss. Dazu entfernen wir
unsere Arbeitskopie durch update -A wieder von dem Zweig
(Zweigmarkierungen verhalten sich diesbezüglich wie andere bindende
Eigenschaften) und führen dann einen Diff gegen die
Hauptentwicklungslinie, die wir gerade verlassen haben, durch:
user@linux ~$
cvs -q update -A
U hello.c
U b-subdir/random.c
user@linux ~$
cvs -q diff -c -r Release-1999_05_01-bugfixes
Index: hello.c
===============================================
RCS file: /usr/local/cvs/myproj/hello.c,v
retrieving revision 1.5.2.1
retrieving revision 1.6
diff -c -r1.5.2.1 -r1.6
*** hello.c 1999/05/05 00:15:07 1.5.2.1
--- hello.c 1999/05/04 20:19:16 1.6
***************
*** 4,9 ****
main ()
{
printf ("Hello, world!\n");
! printf ("between hello and good-bye\n");
printf ("Goodbye, world!\n");
}
--- 4,10 ----
main ()
{
printf ("Hello, world!\n");
! printf ("between hello and goodbye\n");
printf ("Goodbye, world!\n");
+ /* a comment on the last line */
}
Index: b-subdir/random.c
===========================================
RCS file: /usr/local/cvs/myproj/b-subdir/random.c,v
retrieving revision 1.2.2.1
retrieving revision 1.2
diff -c -r1.2.2.1 -r1.2
*** b-subdir/random.c 1999/05/05 00:15:07 1.2.2.1
--- b-subdir/random.c 1999/04/19 06:35:27 1.2
***************
*** 4,8 ****
void main ()
{
! printf ("A random number.\n");
}
--- 4,8 ----
void main ()
{
! printf ("a random number\n");
}
user@linux ~$
|
Der Diff zeigt, dass good-bye in der verzweigten Revision von hello.c
mit einem Bindestrich geschrieben wird und dass die Revision der
Hauptentwicklungslinie dieser Datei einen Kommentar am Ende enthält,
den die andere Revision nicht enthält. Außerdem enthält die
Zweigrevision von random.c ein großes A und einen Punkt, wohingegen
die Hauptentwicklungslinie dies nicht beinhaltet.
Um die Veränderungen des Zweiges tatsächlich in die aktuelle
Arbeitskopie zu übernehmen, wird das update-Kommando mit der Option -j
verwendet (das gleiche j für join, das wir auch verwendet haben um
eine Datei in eine ältere Revision zurückzuführen):
user@linux ~$
cvs -q update -j Release-1999_05_01-bugfixes
RCS file: /usr/local/cvs/myproj/hello.c,v
retrieving revision 1.5
retrieving revision 1.5.2.1
Merging differences between 1.5 and 1.5.2.1 into hello.c
RCS file: /usr/local/cvs/myproj/b-subdir/random.c,v
retrieving revision 1.2
retrieving revision 1.2.2.1
Merging differences between 1.2 and 1.2.2.1 into random.c
user@linux ~$
cvs -q update
M hello.c
M b-subdir/random.c
user@linux ~$
cvs -q ci -m "merged from branch Release-1999_05_01-bugfixes"
Checking in hello.c;
/usr/local/cvs/myproj/hello.c,v <ó hello.c
new revision: 1.7; previous revision: 1.6
done
Checking in b-subdir/random.c;
/usr/local/cvs/myproj/b-subdir/random.c,v <ó random.c
new revision: 1.3; previous revision: 1.2
done
user@linux ~$
|
Dies bringt die Veränderungen von der Wurzel des Zweiges an dessen
Spitze und verschmilzt diese mit der aktuellen Arbeitskopie (die
daraufhin diese Veränderungen genau so aufweist, als wäre
sie von Hand in diesen Zustand gebracht worden). Diese Veränderungen
werden dann per commit in die Hauptentwicklungslinie eingebunden, da
sich nichts im Archiv verändert, wenn merge auf eine Arbeitskopie
angewendet wird.
Obwohl in diesem Beispiel keine Konflikte auftraten, ist es möglich
(sogar wahrscheinlich), dass welche bei einem normalen Merge
auftreten. Ist dies der Fall, müssen diese, wie bei jedem anderen
Konflikt auch, zuerst aufgelöst und dann wieder per commit eingebracht
werden.
Mehrfache Verschmelzung
Manchmal wird ein Zweig aktiv weiterentwickelt, obwohl die
Hauptentwicklungslinie bereits damit verschmolzen wurde. Dies kann zum
Beispiel dann vorkommen, wenn ein zweiter Fehler in der letzten
veröffentlichten Version gefunden wird und in dem Zweig behoben werden
muss. Vielleicht hat jemand den Witz in random.c nicht verstanden,
also muss in dem Zweig eine Zeile zu dessen Erklärung eingefügt
user@linux ~$
pwd
/home/whatever/myproj_branch
user@linux ~$
cat b-subdir/random.c
/* Print out a random number. */
#include <stdio.h>
void main ()
{
printf ("A random number.\n");
printf ("Get the joke?\n");
}
user@linux ~$
|
und per commit abgeschickt werden. Wenn diese Fehlerbereinigung nun
auch in der Hauptentwicklungslinie durchgeführt werden muss, könnte
man versucht sein, das gleiche update-Kommando wie zuvor in der
Arbeitskopie der Hauptentwicklungslinie durchzuführen, um eine
Neuverschmelzung zu machen:
user@linux ~$
cvs -q update -j Release-1999_05_01-bugfixes
RCS file: /usr/local/cvs/myproj/hello.c,v
retrieving revision 1.5
retrieving revision 1.5.2.1
Merging differences between 1.5 and 1.5.2.1 into hello.c
RCS file: /usr/local/cvs/myproj/b-subdir/random.c,v
retrieving revision 1.2
retrieving revision 1.2.2.2
Merging differences between 1.2 and 1.2.2.2 into random.c
rcsmerge: warning: conflicts during merge
user@linux ~$
|
Wie Sie sehen können, hatte dies nicht den erwarteten Effekt - es wird
ein Konflikt angezeigt, obwohl die Kopie der Hauptentwicklungslinie
nicht verändert wurde und deshalb keine Konflikte zu erwarten waren.
Das Problem ist, dass das update-Kommando genau wie beschrieben
arbeitete: Es versuchte alle Veränderungen zwischen der Zweigwurzel
und -spitze mit der aktuellen Arbeitskopie zu verschmelzen. Das
Problem hier ist, dass einige dieser Veränderungen bereits mit dieser
Arbeitskopie verschmolzen wurden. Daher der Konflikt:
user@linux ~$
pwd
/home/whatever/myproj
user@linux ~$
cat b-subdir/random.c
/* Print out a random number. */
#include <stdio.h>
void main ()
{
<<<<<<<< random.c
printf ("A random number.\n");
=======
printf ("A random number.\n");
printf ("Get the joke?\n");
>>>>>>> 1.2.2.2
}
user@linux ~$
|
Man könnte nun alle diese Konflikte durchgehen und von Hand auflösen -
es ist gewöhnlich nicht schwer herauszufinden, was in jeder Datei
verändert werden muss. Dennoch ist es besser, Konflikte von
vornherein zu verhindern. Durch die Angabe von zwei -j-Optionen
anstatt von einer kann man nur jene Veränderungen bekommen, die nach
dem Zeitpunkt der letzten Verschmelzung mit der Spitze stattgefunden
haben, anstatt alle Veränderungen des Zweiges von der Wurzel bis zur
Spitze. Das erste -j gibt dabei den Startpunkt auf dem Zweig und das
zweite einfach den Zweignamen an (welcher die Spitze des Zweiges
einschließt).
Die Frage ist nur, wie kann der Punkt der letzten Verschmelzung auf
dem Zweig spezifiziert werden? Eine Möglichkeit ist, ein Datum mit dem
Namen der Zweigmarkierung anzugeben. CVS bietet dafür eine eigene
Syntax:
user@linux ~$
cvs -q update -j "Release-1999_05_01-bugfixes:2 days ago" \
-j Release-1999_05_01-bugfixes
RCS file: /usr/local/cvs/myproj/b-subdir/random.c,v
retrieving revision 1.2.2.1
retrieving revision 1.2.2.2
Merging differences between 1.2.2.1 and 1.2.2.2 into random.c
user@linux ~$
|
Folgt dem Namen der Zweigmarkierung ein Doppelpunkt und ein Datum (in
einem der üblichen CVS-Datumsformate), werden von CVS nur
Veränderungen berücksichtigt, die nach diesem Datum stattfanden. Wenn
Sie also wissen, dass die ursprüngliche Bereinigung des Fehlers vor
drei Tagen per commit in den Zweig einfloss, würde das vorstehende
Kommando nur die neue Fehlerbereinigung einfließen lassen.
Ein besserer Weg ist, wenn man im Voraus plant, den Zweig nach jeder
Fehlerbereinigung zu markieren (nur eine normale Markierung, es soll
kein neuer Zweig oder etwas Ähnliches damit begonnen werden). Stellen
Sie sich vor, nach der Beseitigung des Fehlers in dem Zweig und
anschließendem commit führen Sie Folgendes in der Arbeitskopie des
Zweiges aus:
user@linux ~$
cvs -q tag Release-1999_05_01-bugfixes-fix-number-1
T README.txt
T hello.c
T a-subdir/whatever.c
T a-subdir/subsubdir/fish.c
T b-subdir/random.c
user@linux ~$
|
Dann, wenn es Zeit wird, die zweite Veränderung mit der
Hauptentwicklungslinie zu verschmelzen, können Sie diese sinnvoll
platzierte Markierung verwenden, um die vorangegangenen Revisionen
einzuschränken:
user@linux ~$
cvs -q update -j Release-1999_05_01-bugfixes-fix-number-1 \
-j Release-1999_05_01-bugfixes
RCS file: /usr/local/cvs/myproj/b-subdir/random.c,v
retrieving revision 1.2.2.1
retrieving revision 1.2.2.2
Merging differences between 1.2.2.1 and 1.2.2.2 into random.c
user@linux ~$
|
Dies ist natürlich wesentlich besser als zu versuchen, sich daran zu
erinnern, wann man die eine oder andere Veränderung gemacht hat,
funktioniert aber nur, wenn man daran denkt, den Zweig jedes Mal zu
markieren, wenn man ihn mit der Hauptentwicklungslinie verschmolzen
hat. Die Lehre daraus ist also früh zu markieren, und das oft! Es ist
besser, sich durch zu viele Markierungen kämpfen zu müssen (solange
diese aussagekräftige Namen haben), als zu wenige zu haben. In den
vorangegangenen Beispielen war es zum Beispiel nicht notwendig, dass
die neuen Zweigmarkierungen einen ähnlichen Namen wie der Zweig selbst
haben. Obwohl ich diesen Release-1999_05_01-bugfixes-fix-number-1
genannt habe, könnte er genauso gut fix1 heißen. Dennoch ist die
erste Variante vorzuziehen, weil diese den Namen des Zweiges
beinhaltet und so kaum mit einer Markierung eines anderen Zweiges
verwechselt werden kann. (Denken Sie daran, dass Markierungsnamen
lediglich innerhalb einer Datei einmalig sind, nicht innerhalb von
Zweigen. Es kann keine zwei Markierungen fix1 innerhalb einer Datei
geben, auch wenn sich diese auf Revisionen in unterschiedlichen
Zweigen beziehen.)
Markierungen und Zweige ohne Arbeitskopie erstellen
Wie vorher schon erwähnt, beeinflusst das Markieren das Archiv, nicht
die Arbeitskopie. Dies wirft die Frage auf: Warum wird überhaupt eine
Arbeitskopie zum Markieren benötigt? Der einzige Zweck ist, das
Projekt und die Revisionen der verschiedenen Dateien innerhalb des
Projektes anzugeben, auf die sich die Markierung beziehen soll. Würde
man das Projekt und die Revisionen unabhängig von der Arbeitskopie
angeben, würde gar keine Arbeitskopie benötigt.
Dies ist auch möglich: mit dem rtag-Kommando (repository tag,
Markieren im Archiv). Dies ist sehr ähnlich zu tag; ein paar Beispiele
sollen seine Verwendung erläutern. Gehen wir zurück zu dem
Augenblick, als der erste Fehler berichtet wurde und wir einen Zweig
erzeugen mussten, der zum Zeitpunkt der letzten veröffentlichten
Version seine Wurzel hatte. Es wurde dann ein Checkout mit der
Markierung der Veröffentlichung gemacht und anschließend tag -b
darauf angewendet:
user@linux ~$
cvs tag -b Release-1999_05_01-bugfixes
|
Dies erstellte einen Zweig, der bei Release-1999_05_01 verwurzelt
ist. Wir kannten allerdings die Markierung der Veröffentlichung und
hätten diese mit dem rtag-Kommando verwenden können, um die Wurzel
der Verzweigung anzugeben, ohne uns um eine Arbeitskopie kümmern zu
müssen:
user@linux ~$
cvs rtag -b -r Release-1999_05_01 Release-1999_05_01-bugfixes myproj
|
Das ist alles. Dieses Kommando kann von überall innerhalb oder
außerhalb einer Arbeitskopie ausgeführt werden. Die
CVSROOT-Umgebungsvariable müsste natürlich schon auf das Archiv
verweisen, oder man könnte dies mit der -d-Option direkt angeben.
Dies funktioniert ebenso bei Nicht-Verzweigungsmarkierungen, ist aber
weniger nützlich, da dann die Revisionsnummern jeder Datei
nacheinander angegeben werden müssten.(Man könnte sich natürlich
auch mittels einer Markierung darauf beziehen, doch dann wäre ja schon
eine Markierung dieser Revision vorhanden, und warum sollte man dann
noch eine hinzufügen?)
Sie wissen nun genug, um mit CVS zurechtzukommen, und vielleicht auch
schon genug, um mit anderen Leuten an einem Projekt zu arbeiten. Es
gibt immer noch einige weniger wichtige Funktionen, die noch nicht
eingeführt wurden, genau wie einige noch nicht erwähnte nützliche
Optionen zu Funktionen, die bereits erwähnt wurden. Diese werden alle
in entsprechenden, noch kommenden Kapiteln vorgestellt, zusammen mit
Szenarien, in denen sowohl gezeigt wird, wie und wann man diese
einsetzt. Im Zweifelsfall konsultieren Sie das Cederqvist-Handbuch;
dies ist eine unverzichtbare Quelle für jeden ernsthaften CVS-Benutzer.
-
Anm. d. Übers.: engl. directory = Verzeichnis
-
Anm. d. Übers.: engl. hunk = Stück
-
Anm. d. Übers.: engl. sticky = bindend, anhaftend, klebrig
-
Anm. d. Übers.: engl. branch = Zweig, Verzweigung
|
|
 SelfLinux
SelfLinux 